三年ぶりのベトナム行き直前の近況
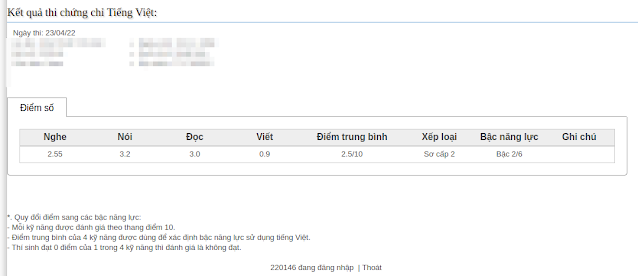
あと10日程で三年ぶりのベトナム行きとなる。 三年前、私はベトナムから帰ってきてこんな記事を書いた。 「ベトナム語:今回もほとんど通じなかった件(南部と北部の発音)」 三年前、そこそこ自分なりにベトナム語を頑張って勉強したつもりであったが、ほぼ全く聴き取れず会話にならなかったことについて、主にアプリで学習した北部発音と自分が毎回訪れている南部では全然発音が異なる事を要因として挙げていた。 さて、その後もベトナム語についていろんな記事を書いているので、その後どのように考えて学習を行っていたかは過去の記事を読み返せばわかる。 コロナ騒ぎによって三年間ベトナムに行けなかったわけであるが、その間、以前にもましてベトナム語の学習を頑張ったのは間違いない。 一応、ホーチミン人文社会科学大学のベトナム語能力試験をオンラインで受けてA2を取得することは出来た。 試験は南部発音だったのでこの三年間南部発音を中心に学習してきたことはプラスに働いた。 そして、いよいよ三年ぶりのベトナム、実際に現地で南部発音を聴き取れるのか? 考えるとドキドキする。 この三年間、オンラインレッスンで何度も何度も発音練習を繰り返していた。 だが、実際にスムーズに会話できるようになったかというと、そうでもない。 いや、そうでもないどころではない、未だかなり低レベルな会話しか出来ない。 要因としてはテキストに沿った発音練習がメインで、本当に自由な会話はさほどしていなかった。 それに、教えてもらった言葉や文法を繰り返し練習していなかった。 なので記憶に定着しておらず、いざというときに出てこないので会話が止まってしまう。 これは最近、過去のレッスンメモを見返していてすごく実感した。 復習と実践がまだ全然足りていない。 それに気がついて、過去のレッスンメモを見ながらレッスン動画を見返し、教えてもらった単語を単語帳に追加するという事をやり始めたのがつい最近 そんな状況の中で、これから私は積極的に新しい先生とオンラインレッスンを行っていく予定。 ベトナム行き直前で悪あがきっぽいけど、まぁでもやれることはやっておいたほうが良いと思う。 どうせだから以前からYouTubeでよく知っている先生にお願いすることにした。 ベトナムから帰ってきたときに、三年前と同じ内容のブログを書かないで済むように今頑張るしか無い!